
Project Description
How Machine Leaning models can predict if a track would be a “Hit” or not, based on song’s audio features.
The dataset I have been using to build the Machine Learning model consists of features for tracks fetched using Spotify's Web API. The tracks are labeled '1' or '0' ('Hit' or not),
'1' implies that this song has featured in the weekly list (Issued by Billboards) of Hot-100 tracks in that decade at least once and is therefore a 'hit'. '0' Implies that the track is not a hot called a 'flop'.The dataset starts at Jan 2010 to Dec 2019.
I have buildt three Machine Learning models, but it has been Random Forest Clasifier that provides the best score, so I have applied Grid Search CV to this model, and then I have evaluated beyond accuracy using ROC curve, Confusion matrix and other evaluation metrics using cross validation, that provides a cross validated accuracy of 0,84.
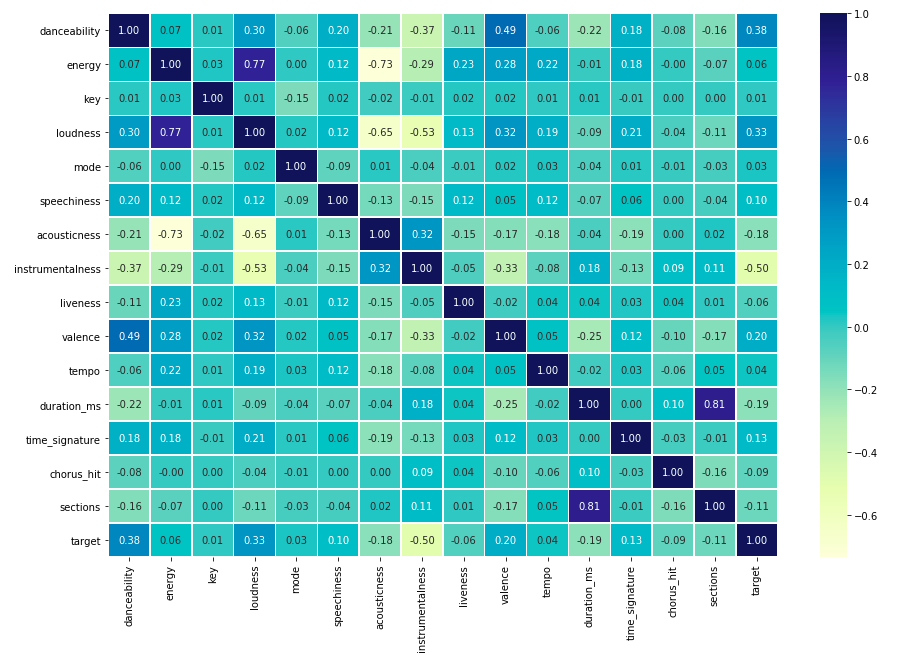
It infers from the model at danceability, loudness and valence are postive correlated with our taget variable, that means if these 3 features goes up, then the track is more likely to be a ”Hit”, on the other hand instrumentalness is negative correlated with out target, instrumental goes down, the target goes up. See below the description of these 4 mentioned features:
danceability: describes how suitable a track is for dancing.
loudness: The overall loudness of a track in decibels (dB).Values typical range between -60 and 0 db.
valence: A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track. Tracks with high valence sound more positive (e.g. happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g. sad, depressed, angry).
instrumentalness: Predicts whether a track contains no vocals. “Ooh” and “aah” sounds are treated as instrumental in this context. Rap or spoken word tracks are clearly “vocal”. The closer the instrumentalness value is to 1.0, the greater likelihood the track contains no vocal content. Values above 0.5 are intended to represent instrumental tracks, but confidence is higher as the value approaches 1.0.
I have been using Python in Jupyter notebook with tools as numpy, pandas, scikit-learn and other Python libraries.
The next step I am working on is, to deploy the model in a web app :)

